Optimal Decay Spectra for Linear Recurrences: Introducing PoST
 Empirical timescale distribution and per-layer allocation
Empirical timescale distribution and per-layer allocation
Linear recurrent models — Mamba-2, RWKV-7, Gated DeltaNet, GLA, RetNet — promise the holy grail of sequence modeling: linear-time processing with constant memory. But there is a dirty secret: most of that memory is wasted.
This post is an informal walkthrough of our paper "Optimal Decay Spectra for Linear Recurrences", where we figure out exactly why this happens and how to fix it with a dead-simple, zero-cost method called PoST (Position-Adaptive Spectral Tapering).
The Setup: How Linear Recurrences Work
A linear recurrent model maintains a hidden state that gets updated at each token:
Each of the channels has its own decay gate . A channel with forgets slowly (long memory), while forgets quickly (short memory). The collection of all these decay rates — the decay spectrum — determines what the model can and cannot remember.
Think of it like having tape recorders, each set to erase at a different speed. Some keep recordings for a long time (slow decay), others overwrite quickly (fast decay). Together, they let you reconstruct a range of past events.
The question is: how should you tune these tape recorders?
The Problem: Minimum-Gap Collapse
Here's what actually happens in practice. When you initialize those decay parameters randomly (as prior diagonal SSMs like S5 and DSS did) or even with structured initializations like HiPPO's linear spacing, something pathological occurs:
The channels clump together.
We prove this rigorously (Lemma 4.1 in the paper), but the intuition is simple. If you throw darts randomly at a number line, the closest pair gets quadratically close together as grows — the minimum gap shrinks as . Two channels with nearly identical decay rates are functionally redundant. You are paying for memory slots but only getting the effective capacity of far fewer.
We call this minimum-gap collapse, and it is not just a theoretical curiosity — you can see it directly in trained models:
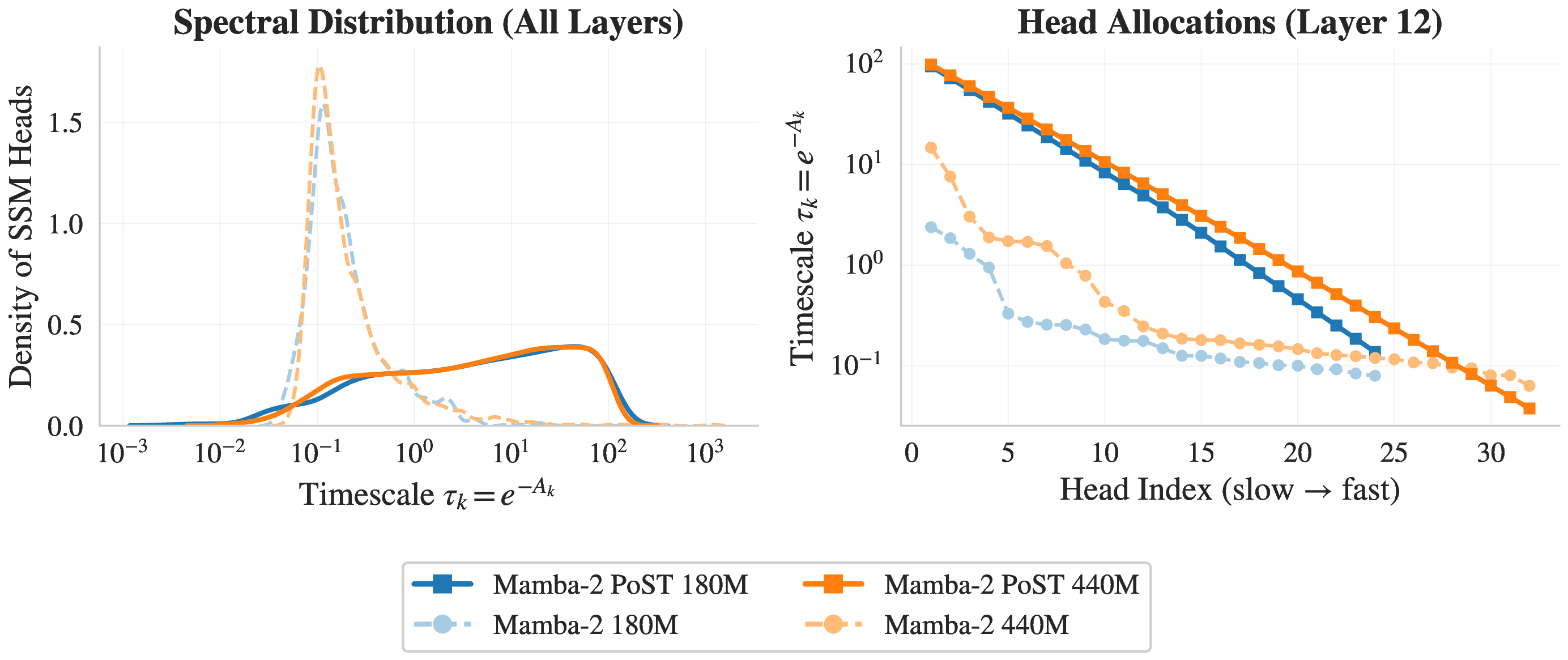
Empirical timescale distribution and per-layer allocation
Look at the left panel. The standard Mamba-2 model's timescale distribution (blue) collapses into a narrow spike — almost all memory channels are tuned to similar fast timescales. Long-range memory is practically nonexistent. The PoST model (orange) spreads its channels across the full timescale range.
The right panel is even more striking: within a single layer, the baseline model's channels flatten out at the same timescale, while PoST forms a perfect geometric ladder on the log scale.
Here is the full Layer × Head heatmap showing every single head in trained 180M and 440M models:
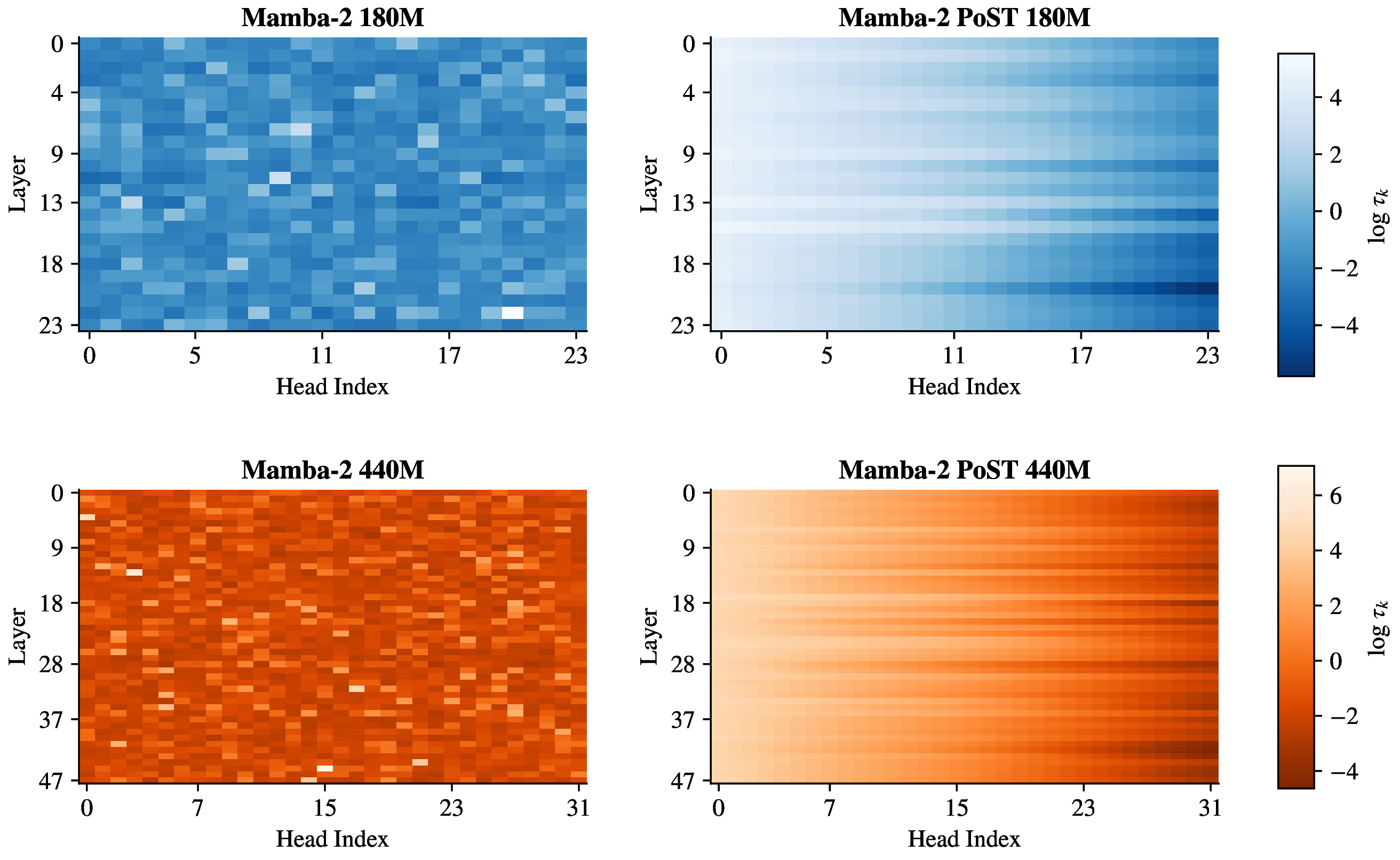 Layer × Head heatmap of log-timescales
Layer × Head heatmap of log-timescales
The baseline (left) is nearly uniform in color — all heads at every layer collapse to the same band of fast timescales. PoST (right) shows a smooth gradient because the ordering is structurally enforced by the parameterization itself. This is not a visualization trick; it is an intrinsic property of PoST's learned weights.
The Theory: What Should the Ideal Spectrum Look Like?
Before jumping to a fix, we need to know what the target is. What is the optimal memory allocation for a linear recurrent model?
We approach this from first principles. The key insight comes from a well-known empirical fact about natural language: correlations in text are approximately scale-free. The power spectral density follows a law — there is no single "characteristic timescale" that matters more than others. Short-range syntax, paragraph-level coherence, and long-range narrative arcs all carry roughly equal predictive information per logarithmic octave.
We formalize this with three conditions:
-
Hierarchical Stationarity. The correlation structure looks the same at every scale. Coarse-graining the sequence by aggregating consecutive tokens just rescales the amplitude by , without changing the shape. This is the stochastic analogue of the renormalization group from statistical physics.
-
Resolution Irreducibility. The smallest meaningful unit is one token — sub-token dependencies carry no additional predictive information. This is an information-theoretic Nyquist condition.
-
Logarithmic Information Equipartition. Every doubling of the context window contributes the same amount of new predictive information. Tokens at lag 1–2 are as informative (per octave) as tokens at lag 1000–2000.
From these three conditions alone, we derive that at position with memory channels, the minimax-optimal timescales are:
This is a geometric progression on . The slowest channel spans the entire observed context (), the fastest resolves individual tokens (), and everything in between is evenly spaced on the log scale.
The crucial insight is that the optimal spectrum is not fixed — it grows with position. At token 100, the slowest channel should cover 100 steps. At token 10,000, it should reach 10,000 steps back. The entire spectrum continuously adapts to the observed context.
Diagnosing the Failures
Before presenting PoST, it helps to understand precisely how existing strategies fall short.
Random Initialization:
When log-decay rates are drawn independently, the minimum spectral gap collapses to , causing maximum coherence between adjacent channels to approach 1 almost surely (Lemma 4.1). This forces the maximum gap to expand to , bottlenecking the overall minimax approximation error at — a sub-exponential rate far worse than the optimum.
Linear Spacing (HiPPO / S4D):
Linearly spaced eigenvalues () avoid the minimum-gap collapse: the spacing is regardless of . However, they reduce exponential-sum approximation to polynomial approximation, where the algebraic singularity of power-law kernels at imposes a fundamental barrier. Together with the Bernstein ellipse argument, we show (Lemma 4.2) that the minimax error is lower-bounded by:
For practical long-context regimes where , the exponential factor is neutralized, and the effective rate degrades to — merely algebraic.
The Geometric Optimum:
Geometric spacing escapes both traps. Log-decay rates of the form correspond exactly to the Zolotarev nodes that achieve the logarithmic capacity of the condenser in Gonchar–Rakhmanov rational approximation theory. The resulting minimax rate is an un-degraded exponential:
This is exponentially better than both alternatives, and geometric spacing is asymptotically necessary to attain this limit.
The Fix: PoST
PoST resolves both the shape and scale of the spectrum through two synergistic components.
Component 1: Spectral Reparameterization
Instead of letting each decay parameter be independent (which causes minimum-gap collapse), we reparameterize them through a cumulative structure:
Since for all , this guarantees by construction — no matter what gradients the optimizer computes. Channels can never collide, and the non-degeneracy of spectral coherence is formally guaranteed (Proposition 4.4).
We initialize all gaps equally (), giving geometric spacing from the start. And this spacing is minimax optimal (Theorem 4.5): it achieves the exponential rate , while the linear spacing used by HiPPO/S4D/Mamba-2 can only achieve a practically algebraic rate. Geometric spacing is also asymptotically necessary — any non-geometric configuration forfeits the optimal exponential limit.
Component 2: Position-Adaptive Scaling
Spectral Reparameterization fixes the geometric shape, but the spectrum's scale remains static. And a static spectrum designed for training length suffers from a severe scale mismatch: at position , only channels are effective, wasting a fraction of the state capacity (Proposition 4.5).
Position-Adaptive Scaling eliminates this waste:
At early positions (small ), even the "slow" channels decay quickly — appropriate because there is little context to remember. As the sequence grows, slow channels are progressively slowed down, automatically extending their memory horizon to match the expanding context.
This linear taper is provably the unique continuous allocation that maintains geometric spacing at every position while covering the full dependency range (Theorem 4.6). The proof is a short if-and-only-if algebraic chain: geometric preservation plus boundary anchoring uniquely determines the taper.
Bonus: Fractional Invariance. This unique scaling induces a remarkable behavioral property. The slowest channel () depends only on the fractional lag — its impulse response is perfectly scale-free. The fastest channel () depends only on the absolute lag — it resolves token-level features regardless of position. Intermediate channels smoothly interpolate between these extremes. The model's memory becomes inherently multi-resolution without any explicit mechanism.
Here is what the learned taper looks like after pre-training on FineWeb-Edu:
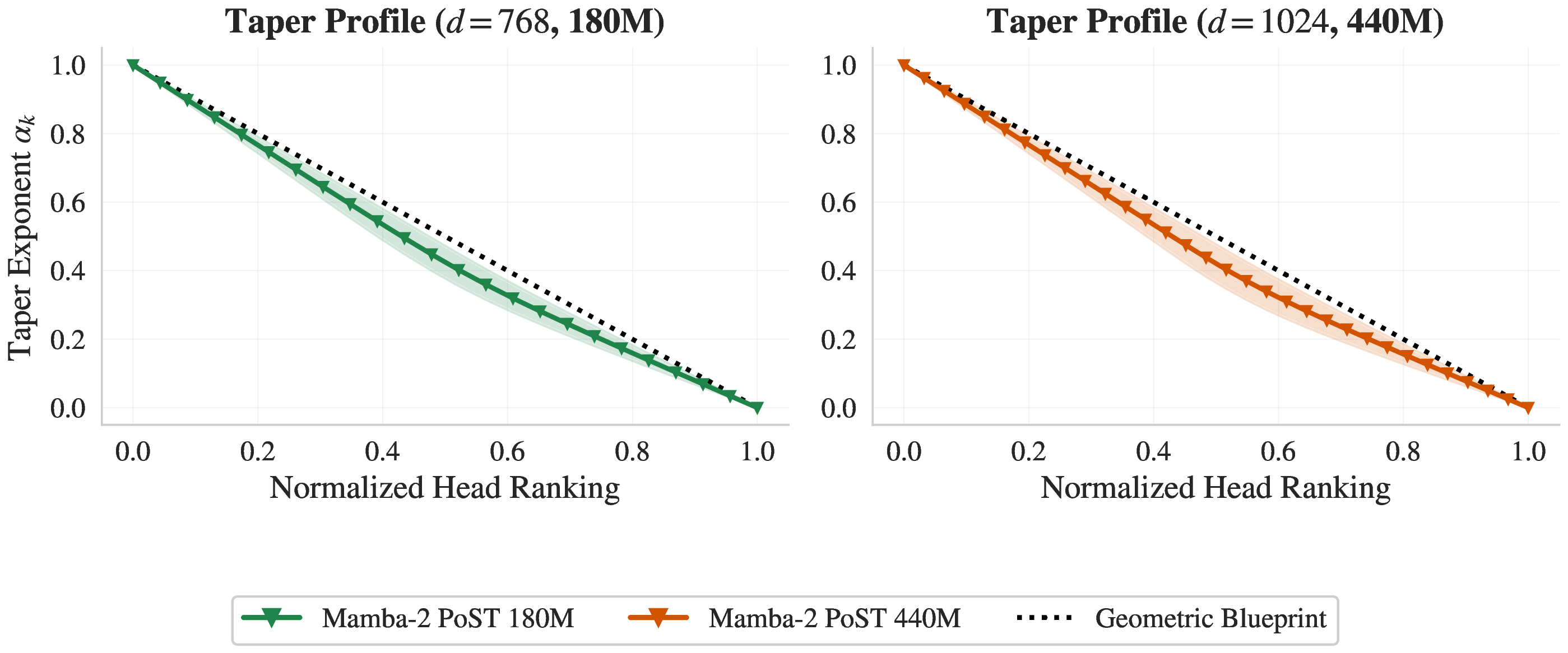 Learned normalization taper
Learned normalization taper
The dashed black line is the theoretical ideal ; the colored lines are what the model actually learns. They align almost perfectly — natural language optimization inherently converges to the theoretically predicted memory allocation.
The Punchline
PoST is:
- A drop-in reparameterization — works on any diagonal linear recurrence (Mamba-2, RWKV-7, Gated DeltaNet, GLA, RetNet)
- Zero additional cost — same computational complexity, same state shape, same inference cost (Proposition 4.9)
- No loss of expressiveness — the Spectral Reparameterization map is surjective onto all strictly ordered spectra (Proposition 4.10)
You change a few lines in the decay computation and get a better model for free.
Does It Work? Experiments
MQAR: Controlled Synthetic Benchmark
We start with Multi-Query Associative Recall (MQAR) — a synthetic task where the model stores key–value pairs and must retrieve all values. We set , train at , and test at up to 8× extrapolation (). Here are the results across five architectures and three state sizes:
State = 64K:
| Model | 512 | 1K | 2K | 4K | Avg |
|---|---|---|---|---|---|
| Mamba-2 | 100.0 | 96.8 | 62.2 | 18.9 | 69.5 |
| +PoST | 100.0 | 97.4 | 68.3 | 25.1 | 72.7 |
| RWKV-7 | 100.0 | 100.0 | 96.1 | 39.2 | 83.8 |
| +PoST | 100.0 | 100.0 | 98.5 | 52.9 | 87.8 |
| Gated DeltaNet | 100.0 | 100.0 | 92.0 | 42.4 | 83.6 |
| +PoST | 100.0 | 100.0 | 95.3 | 48.4 | 85.9 |
| GLA | 100.0 | 97.8 | 67.2 | 20.8 | 71.5 |
| +PoST | 100.0 | 96.0 | 62.1 | 20.7 | 69.7 |
| RetNet | 99.9 | 47.1 | 2.3 | 0.0 | 37.3 |
| +PoST | 100.0 | 96.0 | 62.1 | 20.7 | 69.7 |
State = 32K:
| Model | 512 | 1K | 2K | 4K | Avg |
|---|---|---|---|---|---|
| Mamba-2 | 99.2 | 85.2 | 41.3 | 11.6 | 59.4 |
| +PoST | 99.8 | 92.1 | 51.6 | 13.2 | 64.2 |
| RWKV-7 | 100.0 | 100.0 | 80.1 | 9.5 | 72.4 |
| +PoST | 100.0 | 100.0 | 98.0 | 28.5 | 81.6 |
| Gated DeltaNet | 100.0 | 96.4 | 56.7 | 15.9 | 67.2 |
| +PoST | 100.0 | 99.9 | 88.9 | 39.6 | 82.1 |
| RetNet | 99.9 | 63.2 | 6.0 | 0.3 | 42.3 |
| +PoST | 99.9 | 93.9 | 54.8 | 16.9 | 66.4 |
RetNet goes from 37.3% → 69.7% at state=64K. RWKV-7 at state=32K jumps from 72.4% → 81.6%. Gated DeltaNet at state=32K leaps from 67.2% → 82.1%. PoST improves nearly every architecture across nearly every setting.
Language Modeling at Scale (180M–440M)
We pretrain Mamba-2, RWKV-7, and Gated DeltaNet on FineWeb-Edu at 180M and 440M parameters. Within each pair, the models are identical except for the decay parameterization:
| Model | Avg (Baseline) | Avg (PoST) |
|---|---|---|
| Mamba-2 180M | 38.7 | 38.8 |
| RWKV-7 180M | 39.8 | 40.6 |
| Gated DeltaNet 180M | 39.1 | 39.8 |
| Mamba-2 440M | 42.2 | 42.5 |
Consistent gains from changing nothing but how the decay parameters are structured.
NIAH: Long-Range Retrieval
This is where PoST shines brightest. Needle-In-A-Haystack tests whether the model can find and reproduce a specific sentence buried in a long distractor context.
For Mamba-2 180M, PoST lifts the average NIAH score from 6.3% to 18.8% — a 3× improvement. The gains are even more dramatic on harder multi-needle variants (MultiKey, MultiQuery, MultiValue). At 440M, it goes from 24.4% to 28.0%.
For Gated DeltaNet, PoST yields a moderate overall improvement (28.9% → 29.8%). For RWKV-7, which already has a strong baseline, performance remains highly competitive.
These results directly confirm the theory: minimum-gap collapse was the bottleneck for Mamba-2's long-range memory, and PoST's geometric spacing plus position-adaptive scaling fix it.
Why This Matters
The deeper lesson goes beyond any single architecture. Linear recurrent models have a finite state budget — and the way you allocate that budget across timescales matters enormously. Random or linearly-spaced allocations waste capacity on redundant channels while leaving critical frequency bands unserved.
PoST is the theoretically optimal solution to this allocation problem, and it reduces to a two-line change in any compatible forward pass. We are scaling to 1.5B parameters on 30B tokens, and we expect the advantages to become even more pronounced at scale — particularly when state capacity is the bottleneck.
The paper is available at arXiv, and the code is open-source at github.com/SiLifen/PoST.